這一篇會用一個例子來介紹 sync.WaitGroup 怎麼使用,然後也來複習一下 goroutine 與 channel 的使用.
假設有 3 個區域,然後利用 K-means 演算法將 3 個區域個別分成 5 群,找出人口最密集的 5 個位置
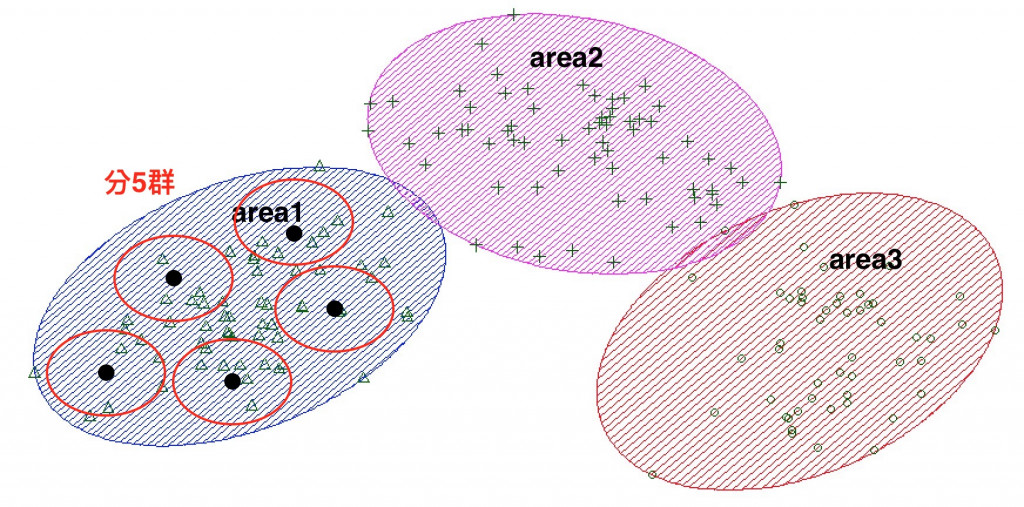
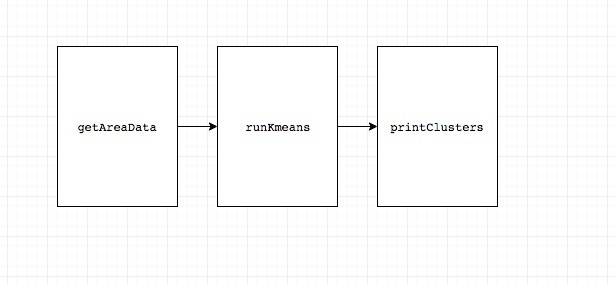
這邊分成主要有 3 個工作 :
1.先畫區域的點(getAreaData)
2.跑 k-means 演算法(runKmeans)
3.印出 3 個區域的 5 個群中心點(printClusters)
參考 go-kmeans
go get github.com/muesli/kmeans
go get github.com/muesli/clusters
程式範例
package main
import (
"fmt"
"math/rand"
"time"
"github.com/muesli/clusters"
"github.com/muesli/kmeans"
)
func main() {
start := time.Now()
var area1 clusters.Observations
var area2 clusters.Observations
var area3 clusters.Observations
getAreaData(&area1)
getAreaData(&area2)
getAreaData(&area3)
clust1 := runKmeans(area1)
clust2 := runKmeans(area2)
clust3 := runKmeans(area3)
printClusters("area1", clust1)
printClusters("area2", clust2)
printClusters("area3", clust3)
end := time.Now()
executeTime := end.Sub(start)
fmt.Printf("executeTime : %v ", executeTime)
}
func getAreaData(area *clusters.Observations) {
rand.Seed(time.Now().UnixNano())
for x := 0; x < 10000000; x++ {
*area = append(*area, clusters.Coordinates{
rand.Float64(),
rand.Float64(),
})
}
}
func runKmeans(d clusters.Observations) clusters.Clusters {
km := kmeans.New()
clusters, _ := km.Partition(d, 5)
return clusters
}
func printClusters(areaName string, clusters clusters.Clusters) {
for i, c := range clusters {
fmt.Printf("%s Cluster: %d\n", areaName, i)
fmt.Printf("%s Centered at x: %.2f y: %.2f\n", areaName, c.Center[0], c.Center[1])
}
}
執行結果
daniel@Danielde-MBP > /Volumes/Transcend/golang/goHello/src/practice > go run example.go
area1 Cluster: 0
area1 Centered at x: 0.83 y: 0.26
area1 Cluster: 1
area1 Centered at x: 0.25 y: 0.76
area1 Cluster: 2
area1 Centered at x: 0.48 y: 0.27
area1 Cluster: 3
area1 Centered at x: 0.75 y: 0.76
area1 Cluster: 4
area1 Centered at x: 0.15 y: 0.26
area2 Cluster: 0
area2 Centered at x: 0.24 y: 0.16
area2 Cluster: 1
area2 Centered at x: 0.24 y: 0.82
area2 Cluster: 2
area2 Centered at x: 0.76 y: 0.24
area2 Cluster: 3
area2 Centered at x: 0.31 y: 0.48
area2 Cluster: 4
area2 Centered at x: 0.76 y: 0.75
area3 Cluster: 0
area3 Centered at x: 0.24 y: 0.24
area3 Cluster: 1
area3 Centered at x: 0.74 y: 0.84
area3 Cluster: 2
area3 Centered at x: 0.71 y: 0.50
area3 Cluster: 3
area3 Centered at x: 0.76 y: 0.17
area3 Cluster: 4
area3 Centered at x: 0.23 y: 0.75
executeTime : 3m33.862961501s %
沒有使用 goroutine 的寫法,只用單執行緒跑完所有的工作 10000000 個點,全部執行時間花了 3 分 33 秒.
將每個工作分成 goroutine 去跑,那使用了 goroutine 基本上 Main function (也就是 Main goroutine)
就不會去等其他的 goroutine 是否執行完成就直接跑完程式了.那其他的 goroutine 也就斷掉結束了.
在之前的範例(goroutines 那篇)是利用 Scanln 讓 Main goroutine 停下來等待,也就讓其他的 goroutine 有時間去完成.
var input string
fmt.Scanln(&input)
所以 sync.WaitGroup 也就是為了來控制這些 goroutine 讓 Main goroutine 等到所有的 goroutine 都完成工作後再繼續往下執行.
WaitGroup 主要有 3 個功能 Add、Wait、Done.下面的例子就是 Add 6 個 goroutine,然後 Main goroutine 會在 Wait 地方,
等待 6 個 goroutine 都 Done 才會繼續往下執行跑完 Main function.
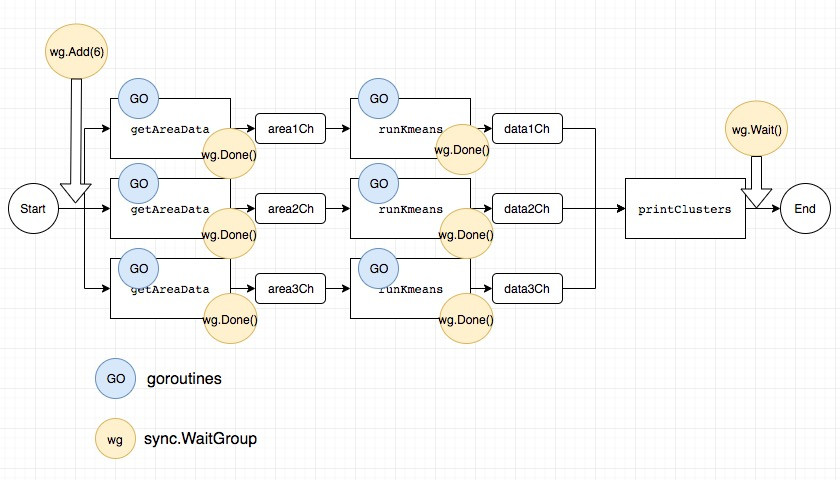
在使用 Done 時有用到 defer 關鍵字,defer 是指在該 function 後執行完後,最後要執行的指令.
通常很適合用在 close io 的時候.
defer wg.Done()
程式範例
package main
import (
"fmt"
"math/rand"
"sync"
"time"
"github.com/muesli/clusters"
"github.com/muesli/kmeans"
)
var wg sync.WaitGroup
func main() {
start := time.Now()
area1Ch := make(chan clusters.Observations)
area2Ch := make(chan clusters.Observations)
area3Ch := make(chan clusters.Observations)
wg.Add(6)
go getAreaData(&area1Ch)
go getAreaData(&area2Ch)
go getAreaData(&area3Ch)
x := make(chan clusters.Clusters)
data2Ch := make(chan clusters.Clusters)
data3Ch := make(chan clusters.Clusters)
go runKmeans(&area1Ch, &data1Ch)
go runKmeans(&area2Ch, &data2Ch)
go runKmeans(&area3Ch, &data3Ch)
printClusters("area1", &data1Ch)
printClusters("area2", &data2Ch)
printClusters("area3", &data3Ch)
wg.Wait()
end := time.Now()
executeTime := end.Sub(start)
fmt.Printf("executeTime : %v ", executeTime)
}
func getAreaData(areaCh *chan clusters.Observations) {
defer wg.Done()
var area clusters.Observations
rand.Seed(time.Now().UnixNano())
for x := 0; x < 10000000; x++ {
area = append(area, clusters.Coordinates{
rand.Float64(),
rand.Float64(),
})
}
*areaCh <- area
}
func runKmeans(areaCh *chan clusters.Observations, dataCh *chan clusters.Clusters) {
defer wg.Done()
km := kmeans.New()
clusters, _ := km.Partition(<-*areaCh, 5)
*dataCh <- clusters
}
func printClusters(areaName string, areaCh *chan clusters.Clusters) {
for i, c := range <-*areaCh {
fmt.Printf("%s Cluster: %d\n", areaName, i)
fmt.Printf("%s Centered at x: %.2f y: %.2f\n", areaName, c.Center[0], c.Center[1])
}
}
執行結果
daniel@Danielde-MBP > /Volumes/Transcend/golang/goHello/src/practice > go run example.go
area1 Cluster: 0
area1 Centered at x: 0.49 y: 0.26
area1 Cluster: 1
area1 Centered at x: 0.75 y: 0.76
area1 Cluster: 2
area1 Centered at x: 0.83 y: 0.26
area1 Cluster: 3
area1 Centered at x: 0.16 y: 0.27
area1 Cluster: 4
area1 Centered at x: 0.25 y: 0.76
area2 Cluster: 0
area2 Centered at x: 0.16 y: 0.73
area2 Cluster: 1
area2 Centered at x: 0.49 y: 0.74
area2 Cluster: 2
area2 Centered at x: 0.75 y: 0.24
area2 Cluster: 3
area2 Centered at x: 0.25 y: 0.23
area2 Cluster: 4
area2 Centered at x: 0.83 y: 0.74
area3 Cluster: 0
area3 Centered at x: 0.25 y: 0.24
area3 Cluster: 1
area3 Centered at x: 0.48 y: 0.74
area3 Cluster: 2
area3 Centered at x: 0.83 y: 0.74
area3 Cluster: 3
area3 Centered at x: 0.75 y: 0.24
area3 Cluster: 4
area3 Centered at x: 0.15 y: 0.73
executeTime : 1m28.470913173s %
使用 goroutine 的寫法,開了 6 個 goroutine 跑完所有的工作 10000000 個點,全部執行時間只花了 1 分 28 秒.
速度比單執行緒快了 1 倍左右.

